
Judged by the presence of artificial intelligence (AI) and machine learning (ML) technologies at 2023 Design Automation Conference (DAC), the premiere event for semiconductor designers, computing hardware for accelerating AI/ML software workloads is finally receiving due attention. According to PitchBook Data, in the first six months of 2023, more than 100 startups designing novel AI/ML computing architectures collected $15.2 billion of venture funding.
With the creation of “transformers,” namely large language models (LLMs) implementing software algorithms, the semiconductor industry has reached an inflexion point. Conceived at Google in 2017, transformers can learn complex interactions between different parts of an entity, be they words in a sentence, pixels in an image, notes in a musical score and more, and generate a translation in a different language, an enhanced image, a new musical score and more.
Transformers turned into the preferred choice for autonomous driving (AD) algorithms for their ability to track multiple interactions between the environment and the AD vehicle. Recently, transformers became the foundation for Generative AI, the most significant new technology since the Internet, introduced by OpenAI’s ChatGPT. Beside the front-runner, well-known transformers include Google PaLM, Meta LLAMA, and others.
However, the advancements in software algorithms spearheaded by transformers have not been paralleled by progress in computing hardware tasked to execute the models. The catch is that cutting-edge dense models are enormous and require massive processing power for learning and even more for inferencing.
Today, the model training process is handled by vast computing farms running for days, consuming immense electric power, generating lots of heat and costing fortunes. Much worse is the inference process. Indeed, it is hitting a wall, defeating GenAI proliferation on edge devices.
Two bottlenecks coincide to defeat the inference process: inadequate memory capacity/bandwidth and insufficient computational power.
While none of the existing edge AI accelerators are well-suited for transformers, the semiconductor industry is at work to correct the deficiency. The demanding computational requirements are tackled on three different levels: innovative architectures, silicon scaling to lower technology nodes, and multi-chip stacking.
Still, the advancements in digital logic do not address the memory bottleneck. To the contrary, they have contributed to a perverse effect, known as “memory wall.”
The memory wall
The memory wall was first devised as a theory by William A. Wulf and Sally A. McKee in an article published in a 1995 issue of the ACM SIGArch Computer Architecture News. It posited that the improvements in processor performance far exceeded those of the memory, and the performance gap has continued to diverge ever since. See Figure 1.
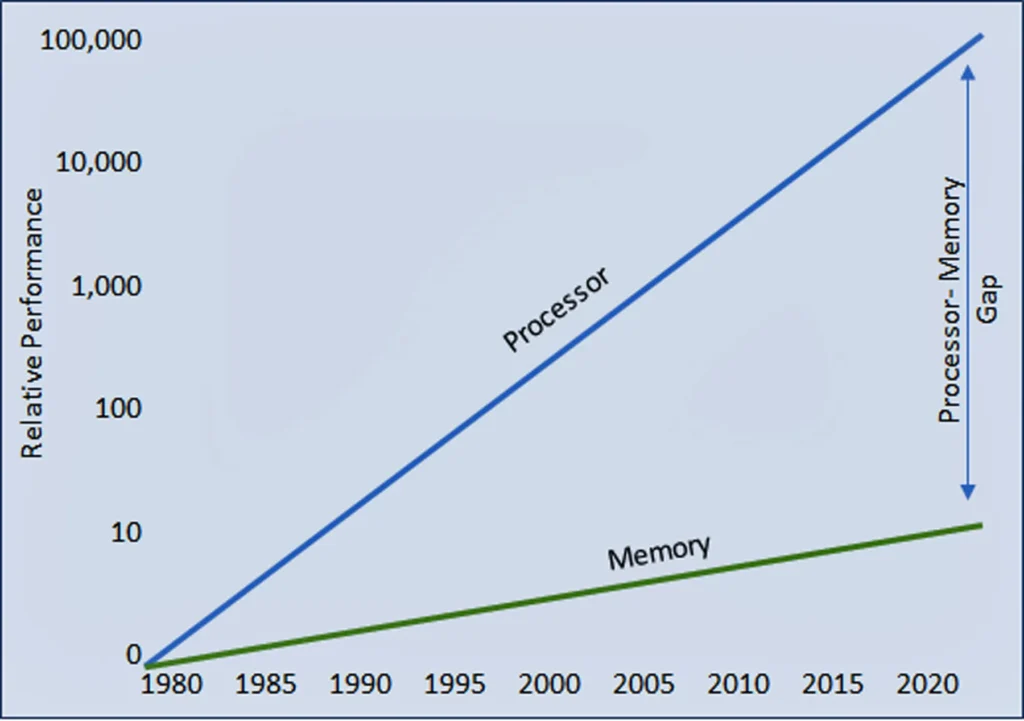
The scenario forces the processor to wait for data from the memory. The higher the performance of the processor, the longer the waiting time. Likewise, the larger the amount of data, the longer the idling time. Both outcomes prevent 100% utilization of the processor.
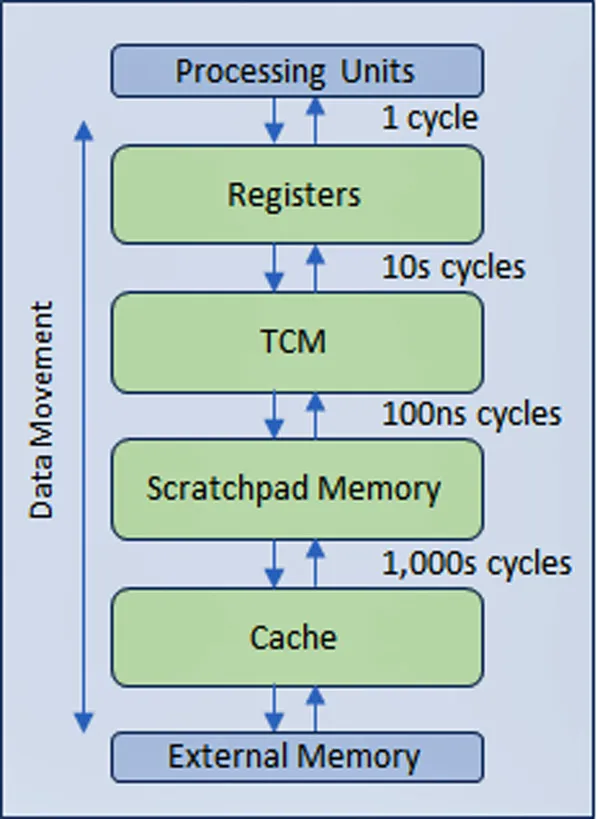
The memory wall has plagued the semiconductor industry for years and is getting worse with each new generation of processors. In response, the industry came up with a multi-level hierarchical memory structure with faster albeit more expensive memory technologies nearer the processor. Closest to the processor are multiple levels of cache that minimize the amount of traffic with the slower main memory and with the slowest external memory.
Inevitably, the more the levels to be traversed, the larger the impact on latency and the lower the processor efficiency. See Figure 2.
The impact on Generative AI: Out of control cost
Today, the impact of the memory wall on Generative AI processing is out of control.
In less than one year, GPT, the foundation model powering ChatGPT, evolved from GPT-2 to GPT-3/GPT-3.5 to the current GPT-4. Each generation inflated the model size and the number of parameters (weights, tokens, and states) by an order of magnitude. GPT-3 models incorporated 175 billion parameters. The most recent GPT-4 models pushed the size to 1.7 trillion parameters.
Since these parameters must be stored in memory, the memory size requirement exploded into terabytes territory. To make things worse, all these parameters must be accessed simultaneously at high speed during training/inference, pushing memory bandwidth to hundreds of gigabytes/sec, if not terabytes/sec.
The daunting data transfer bandwidth between memory and processor brings the processor efficiency to its knees. Recent findings prove that the efficiency of running GPT-4 on cutting-edge hardware drops to around 3%. Meanwhile, the very expensive hardware designed to run these algorithms sits idle 97% of the time.
The lower the implementation efficiency, the more hardware becomes necessary to perform the same task. For example, assuming that a requirement of one petaflop (1,000 teraflops) may be served by two suppliers. The suppliers (A and B) deliver different processing efficiencies, 5% and 50% respectively. Then supplier A could only provide 50 teraflops of effective, not theoretical processing power. Supplier B would provide 500 teraflops of the same. To deliver one petaflops of effective compute power, supplier A would require 20 units of its hardware, but supplier B only 2 units.
Adding hardware to compensate for the inefficiency propels the cost. In July 2023, EE Times reported that Inflection, a Silicon Valley AI startup, is planning to use 22,000 Nvidia H100 GPUs in its supercomputer data center. “A back-of-the-envelope calculation suggests 22,000 H100 GPUs may come in at around $800 million—the bulk of Inflection’s latest funding—but that figure doesn’t include the cost of the rest of the infrastructure, real estate, energy costs and all the other factors in the total cost of ownership (TCO) for on-premises hardware.” Find more on this in Sally Ward-Foxton’s EE Times article “The Cost of Compute: Billion-Dollar Chatbots.”
Digging into publicly available data, a best-guess estimate would lead to a total cost per query in the ballpark of $0.18 per query when the target is 0.2 cents per query, informally established as benchmark by leading AI firms to pay for advertising using the Google model.
Attempts at reducing the usage cost of LLM inference
Intuitively, one approach to improve inference latency and performance would be to increase the batch sizes (the number of concurrent users). Unfortunately, it expands the state data with detrimental impact on memory size and bandwidth.
Another method to reduce the processing power adopted by OpenAI’s GPT-4 consists of using incremental transformers. While performance significantly enhances, it requires one state per user, enlarging the memory capacity needs and taxing the memory bandwidth requirements.
While all attempts ought to be appreciated, the solution must come from a novel chip architecture that will break up the memory wall.
The cost imperative
Unless a solution to reduce the cost of operating ChatGPT or any other large language model can be crafted, the usage model may not be paid for by advertising. Instead, it may have to be based on subscription or similar payment. The implication will impact and limit massive deployment.
Looking at the number of visitors to the OpenAI/ChatGPT website, after three months of exponential growth, the growth curve recently flattened, possibly due to a lowering of the hype surrounding ChatGPT. It could also be the dismay in usage costs. See Figure 3.
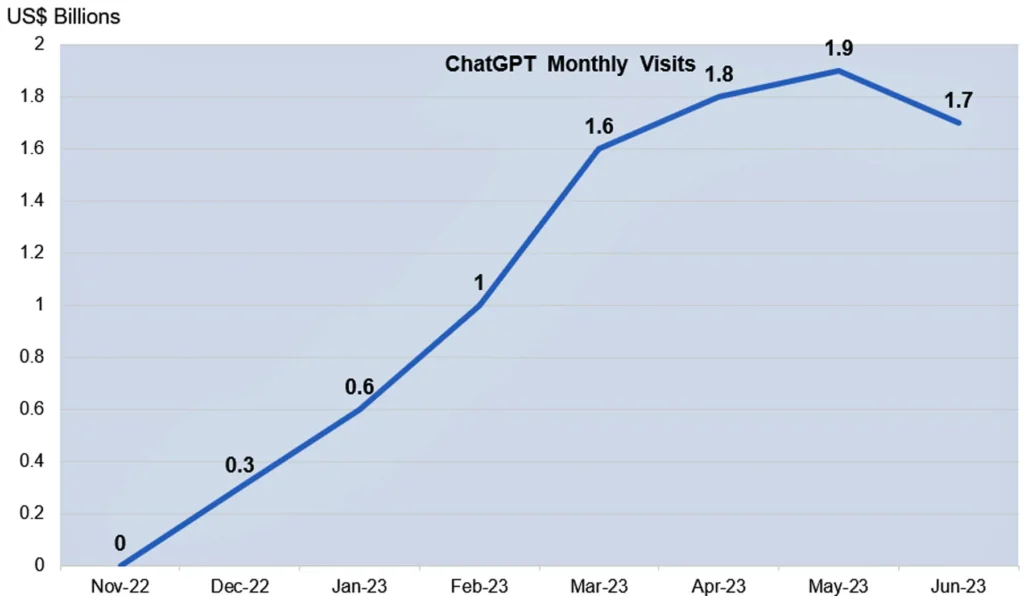
GPT-4 has proven to be unexpectedly daunting to roll out in a commercially viable form. It is fair to assume that there is a GPT-5 lurking in the shadows that will pose an order of magnitude larger challenges.
The Generative AI game will be won by the AI accelerator supplier delivering the highest processing efficiency. It’s a wake-up call for the semiconductor industry.
Dr. Lauro Rizzatti is a verification consultant and industry expert on hardware emulation. Previously, he held positions in management, product marketing, technical marketing, and engineering.