
An emulator’s performance — or its speed of execution — depends on the architecture of the emulation system and the type of deployment.
Source: EETimes

In my previous post, Performance in Hardware Emulators, I discussed the dependency of performance on the type of deployment. In this column, I will examine the relationship between emulation system architectures and their performance.
Emulation performance vs. Emulator architecture
Not all emulators are created equal. Previously, I pointed out that the design capacity and the compilation process are dependent on the architecture of the emulation system. This is also the case for emulation performance.
Let’s remind ourselves that each of the current three hardware emulation suppliers is promoting its own architecture:
- Cadence: Processor-based architecture
- Mentor: Custom emulator-on-chip architecture
- Synopsys: Commercial FPGA-based architecture
While the first two solutions are based on custom chips, the third is built on arrays of commercial FPGAs.
Speed of execution in processor-based emulators
The operation of a processor-based emulator was addressed in the March 12, 2015, EE Times article, Design Compilation in Hardware Emulators. Here, I wish to quickly recall the principles of operation, exemplified and simplified in Figure 1 and Table 1.
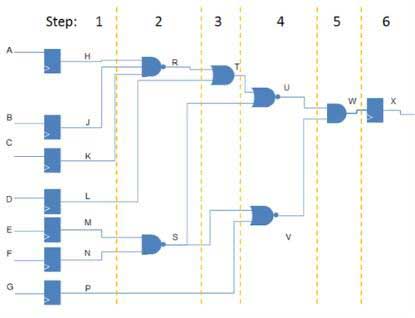
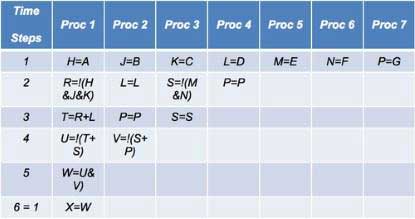
The model of the design under test (DUT) is converted into a data structure stored in memory, and processed by a computing engine consisting of a vast array of Boolean processors; hence the name of this type of emulator. This vast array is typically made up of relatively simple 4-input arithmetic logic units (ALUs), reaching into the multi-millions of elements in fully expanded configurations. All operations are scheduled in time steps and assigned to the processors according to a set of rules the preserve the functional integrity of the DUT.
An emulation cycle consists of running all the processor steps for a complete execution of the design. Large designs typically require hundreds of steps. The more operations carried out in each step, the faster the emulation speed.
During every time step, each processor is capable of performing any function using, as inputs, the results of any prior calculation of any of the processors and/or any design input and/or any memory contents. The more processors available in the emulator, the more parallelism can be achieved for faster emulation time.
Currently, the maximum speed reported by such an implementation in the vendor datasheet hovers around 2MHz. On real system-on-chip (SoC) designs, several users have claimed to reach 1MHz. This would be the case with in circuit emulation (ICE), an embedded testbench, and embedded software acceleration modes. In transaction-based acceleration, however, the Palladium-XP2 is rumored to perform at lower speeds.
Why would this be? High-clocking speed, as important as it is, it is not the only parameter critical to achieving high throughput. This is especially true in transaction mode in which the communication channel between the emulator and the host workstation processing the testbench must have large bandwidth and low latency. An analogy would be a car’s performance versus that of a bus. A car performs at a higher speed than a bus, but a bus carries more people than a car. If the goal is to carry many people from point A to point B, a bus wins.
Palladium-XP2 connects to the host server via separate channels for design-download/waveform-upload and testbench communication. From the bandwidth point of view, it seems that Palladium-XP2 ought to perform more or less as its competitors, but rumors abound to the contrary. Has this to do with latency?
No emulation vendor publishes specifications about bandwidth or latency. Therefore, no specification-based comparison is possible. Whether this is the real cause for the lower speed of execution in transaction-based acceleration of Palladium-XP2 compared to FPGA-based emulators or not, I’ll let someone smarter than I answer this question.
Speed of execution in custom emulation SoC-based emulators
Mentor Graphics employs a custom FPGA in its Veloce2 emulator-on-chip called Crystal2. The interconnection network of the programmable elements inside the FPGAs and between FPGAs follows a patented architecture that secures predictable, repeatable, fast, and congestion-free routing. It removes placement constraints and ensures simple routing and fast compilation. Clock trees are wired on dedicated paths separate from datapaths, leading to predictable and repeatable timing as well as the prevention of timing violations by construction because datapaths are longer than clock paths. Unpredictable timing and hold timing violations cause headaches in users of commercial FPGA-based emulators.
The architecture used in the emulator-on-chip ensures a high level of utilization of the reprogrammable resources. It is designed to ease the process of partitioning a large design into a large array of such custom FPGAs, and it allows for fast place-and-route (P&R).
One spec says it all. Placing and routing one custom FPGA takes about five minutes, not far from 100X faster than P&R of a leading commercial FPGA. The custom FPGA is not meant to be used as a general-purpose FPGA, however, since the capacity of the Crystal2 chip is lower than that offered by the largest commercial FPGAs.
This lower capacity leads to more FPGAs being required to map any given design compared to an emulator based on the largest commercial FPGAs. This, in turn, produces longer propagation delays resulting in a lower emulation speed.
Currently, the maximum speed reported by the vendor in its datasheet is 1.5MHz in both single- and multi-chassis configurations by virtue of its active backplane that interconnects all the chassis together. Mentor Graphics claims that Veloce2 is the only emulation system reaching 1MHz on one-billion gate designs.
This speed is achievable in ICE as well as in all acceleration modes except cycle-based acceleration. Actually, Mentor Graphics states that in TBX with streaming transactors the speed of execution is higher than in ICE mode.
Speed of execution in standard FPGA-based emulators
One benefit of the standard FPGA-based emulator, such as Synopsys’ ZeBu-Server, built with the largest available FPGAs, is that it achieves a higher speed of execution, in the ballpark of 4MHz in one box. Unlike the emulator-on-chip implementation, however, the drop in performance in multi-box configurations is considerable.
Whatever speed is achievable in ICE also is possible in all acceleration modes except cycle-based acceleration.
Summary
At the time of this writing, all three vendors report similar performance in their emulation platforms — in the low, single-digit megahertz speed when measured on single-box configurations.
Of the four deployment modes, ICE and targetless acceleration, whether embedded software acceleration or synthesizable testbench acceleration, reach the maximum speed of execution possible by any specific emulation architecture. In transaction-based acceleration, the processor-based emulator performs at a lower speed of execution than the maximum achievable in ICE and target-less acceleration.
Dr. Lauro Rizzatti is a verification consultant and industry expert on hardware emulation. Previously, Dr. Rizzatti held positions in management, product marketing, technical marketing, and engineering. He can be reached at lauro@rizzatti.com.